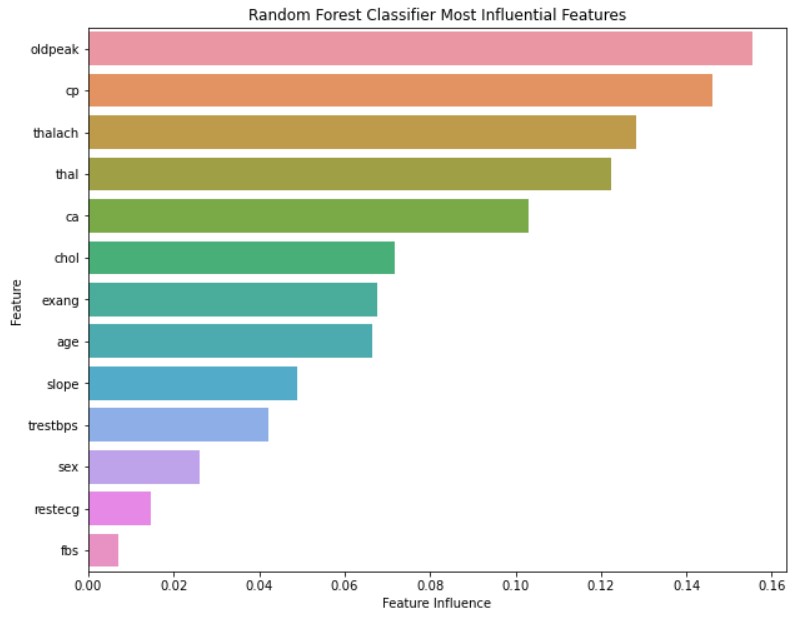
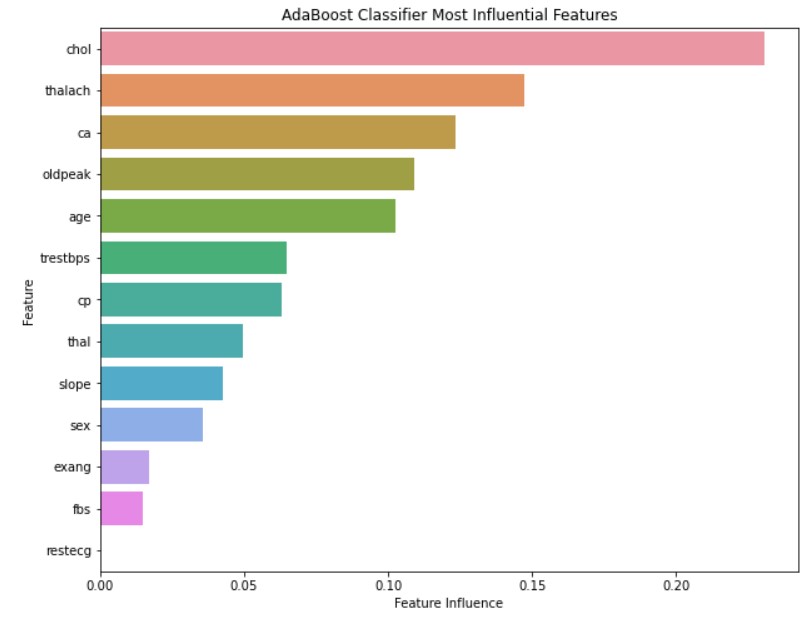
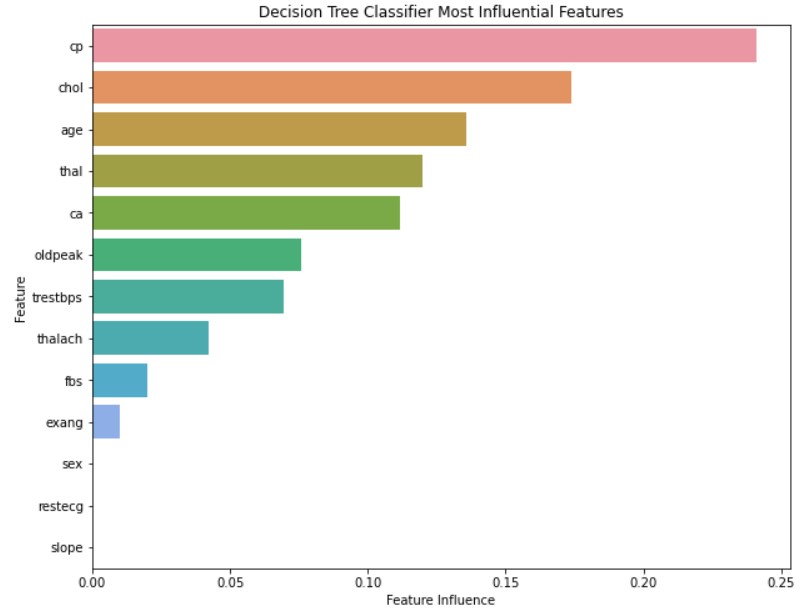
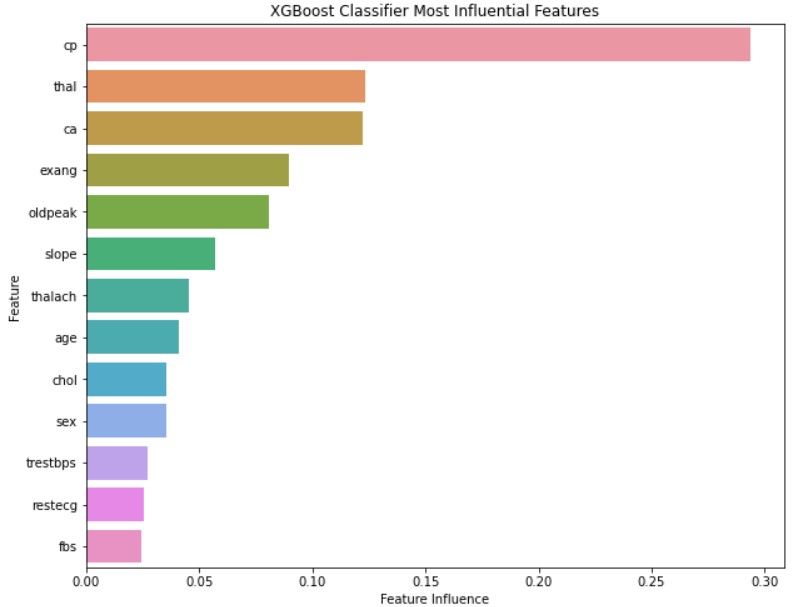

This project explores the Heart Disease Data Set from the UCI Machine Learning Repository, and uses various machine learning models to predict an individual’s risk of having heart disease. The purpose of using several models is for comparison to determine which prediction model is best suited for data sets like this one. Besides comparing the different models, hyperparameters are also tuned to determine their effects on their respective classifiers. In total there are three experimental runs: benchmark, omitted features, and tuned hyperparameters. For the benchmark run, all models are tested with their default hyperparameters. In omitted features, the least significant features determined from the benchmark run are removed and the models are tested again, but with the default hyperparameters. The final run involves using all features, but with each model’s hyperparameters tuned to observe the effects on classification performance.
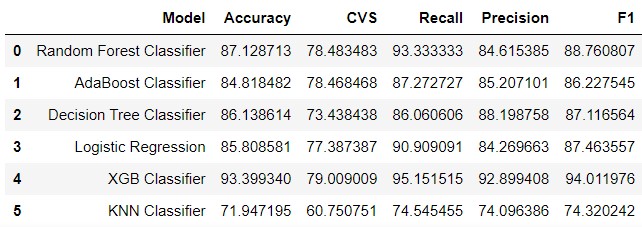
The detailed results, background, and report for this project can be downloaded through the link below, but to summarize, the results of the experimental runs were all quite decent. The general accuracy range of the models was about 80-90%, with KNN being below this metric and XGBoost being above. Overall, the best models for classifying the heart disease data set are XGBoost and Random Forest, as both of these models have F1 scores exceeding 90, and metrics closest to the target accuracy metric of ~95%. The primary reason for these two is because both models have high generalizability and for XGBoost, scalability. Both models are adapted to handle small data sets that more conventional models like logistic regression will suffer with.
Heart Disease Analysis Project Report
Software: Python | Sklearn